pandas or python equivalent of tidyr complete
I have data that looks like this:
I have data that looks like this:
I have a pandas dataframe with the following column names:
I have a pandas data set, called ‘df’.
I am trying to write a paper in IPython notebook, but encountered some issues with display format. Say I have following dataframe df, is there any way to format var1 and var2 into 2 digit decimals and var3 into percentages.
I have a very large data set and I can’t afford to read the entire data set in. So, I’m thinking of reading only one chunk of it to train but I have no idea how to do it. Any thought will be appreciated.
I am trying to unstack a multi-index with pandas and I am keep getting:
I have been trying to normalize a very nested json file I will later analyze. What I am struggling with is how to go more than one level deep to normalize.
I’ve got a pandas dataframe. I want to ‘lag’ one of my columns. Meaning, for example, shifting the entire column ‘gdp’ up by one, and then removing all the excess data at the bottom of the remaining rows so that all columns are of equal length again.
Have a look at the graph below:
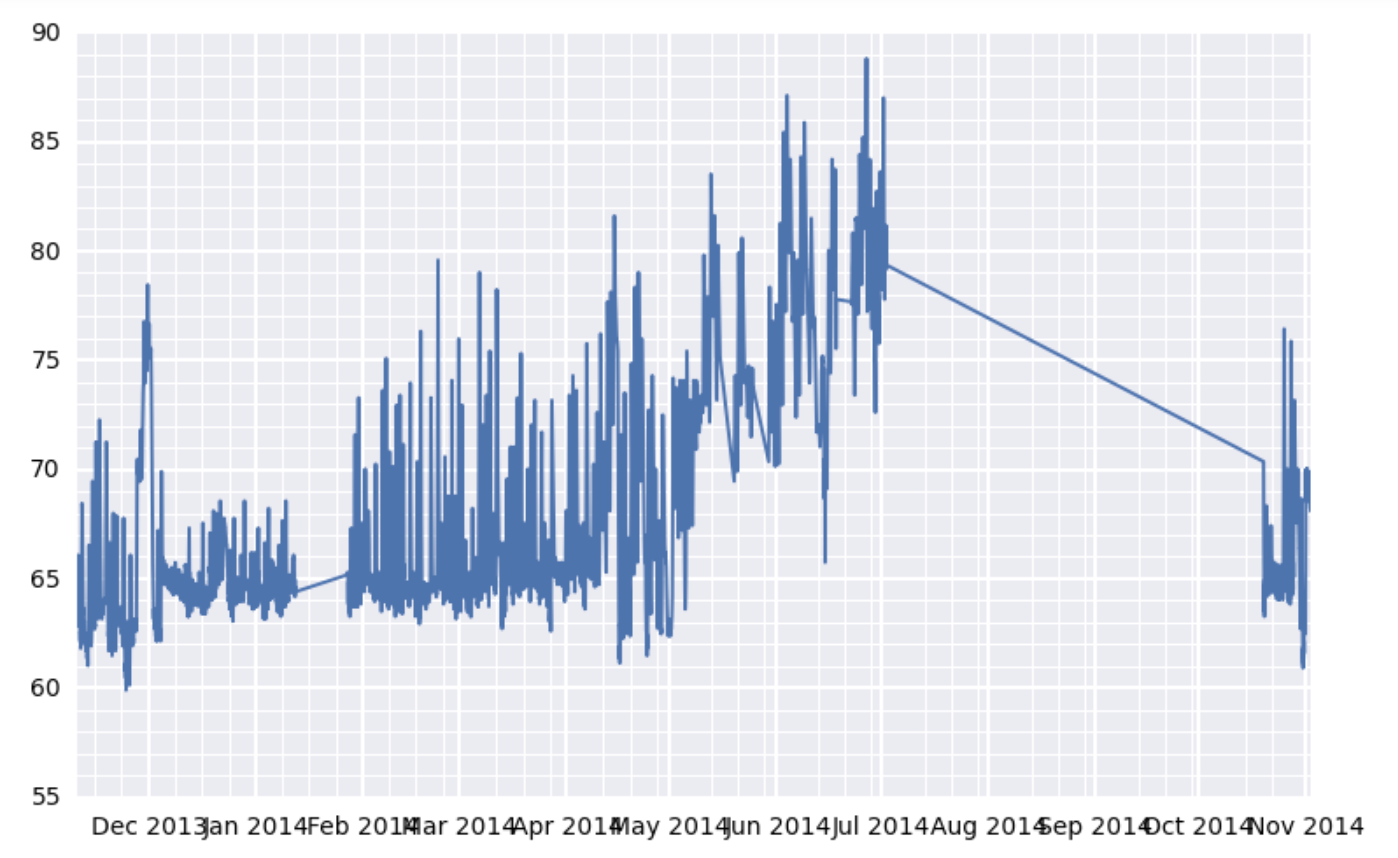
I have an OHLC price data set, that I have parsed from CSV into a Pandas dataframe and resampled to 15 min bars: